Environment Variables¶
The following environment variables can change the runtime behaviour of the SDK. Note, the variables must be set prior to initializing the SDK.
To set an environment variable in your shell, run export VARIABLE_NAME=VARIABLE_VALUE.
TF_NUM_THREADS¶
Used to limit the maximum number of threads used by the SDK.
For a breakdown of how many threads the SDK uses, refer to our FAQ page.
To limit the number of threads used by the SDK threadpools, use the TF_NUM_THREADS environment variable.
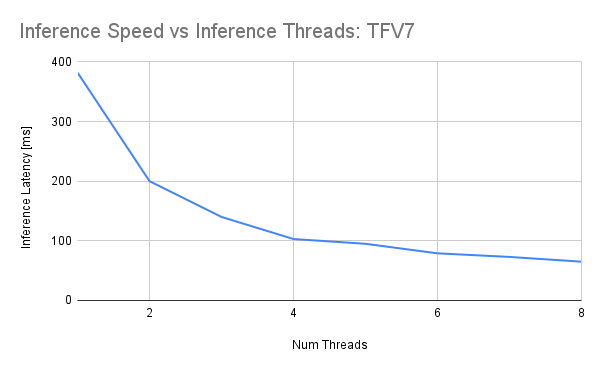
The following graph shows the impact of threads on inference speed.
Must be an integer value greater than 0.
ex. export TF_NUM_THREADS=4
TF_LOG_LEVEL¶
Used to set the log level of the SDK. Options include TRACE, DEBUG, INFO, WARN, ERROR, and OFF.
Default log level is INFO.
ex. export TF_LOG_LEVEL=WARN
HOSTED_DATABASE¶
Specify if the PostgreSQL database is hosted by a service provider such as Digital Ocean, AWS, etc.
A call to Trueface::SDK::createDatabaseConnection() first connects to the template1 database and then queries to see if the specified database exists, and if not, creates it.
Hosted databases often don’t allow connections to this template1 database, therefore throwing an exception on the above SDK method call.
By setting this option to true, the SDK will bypass this initial connection to the template1 database, and will connect directly to the specified database name.
Therefore, if setting this option to true, you must ensure that the specified database exists.
This means you must manually create the desired database within your database server before the SDK can connect to said database.
Possible values include true and false.
Default value is false.
ex. export HOSTED_DATABASE=true
DB_NOTIFICATION_CHECK_FREQUENCY¶
When using the PostgreSQL DatabaseManagementSystem, the SDK launches a background thread to check for any notifications sent out by the database. This ensures that the client node remains in sync with the database. By default, the background thread checks for notifications every 30 seconds. This means that it may take up to 30 seconds for all clients connected to the same database to fall into sync.
This environment variable allows you to dictate how often the SDK checks for notifications, defined as every n seconds. Hence, setting this environment variable to 5 would mean that the SDK checks for notifications every 5 seconds. Do note that the main execution thread is blocked while the background thread checks for notifications, hence why we do not check for notifications all the time.
Must be an integer value greater than 0.
Default value is 30.
ex. export DB_NOTIFICATION_CHECK_FREQUENCY=10
NUM_DB_RETRIES¶
The number of times the SDK should try to reconnect to the database when a disconnect is detected. Although loss of network connection will not trigger a disconnect, other events, such as the PostgreSQL server being stopped, may trigger a disconnect. The SDK will wait 5 seconds between each retry. Hence, if the number of retires is set to 6, then the SDK will try to reconnect 6 times over a total period of 30 seconds. Can be set to 0, in which case the SDK will not try to reconnect to the database.
Must be an integer of value 0 or greater.
Default is 6.
ex. export NUM_DB_RETRIES=12
BYPASS_POSTGRESQL_VERSION_CHECK¶
The SDK links to a specific version of PostgreSQL (you can view the current version number here).
By default, the SDK will not allow you to connect to a PostgreSQL server which has a different major version.
If you would like to bypass this enforcement, you should set this environment variable to true.
However, only do this if you know what you are doing.
Trueface only tests with the specified version of PostgreSQL, and thus can only guarantee defined behaviour with this specific major version of PostgreSQL.
Possible values include true and false.
Default value is false.
ex. export BYPASS_POSTGRESQL_VERSION_CHECK=true