Frequently Asked Questions¶
Note
Some FAQ answers may use C++ code snippets; however, the answers apply to the python bindings SDK too.
For a list of community driven FAQs and answers, please visit our community forums.
How many threads does the SDK use for inference?¶
The SDK inference engines can use up to 8 threads each, but this is dependant on the number of threads your system has.
The Trueface::SDK::batchIdentifyTopCandidate() function is capable of using all the threads on your machine, depending on the number of probe Faceprints provided.
How can I reduce the number of threads used by the SDK?¶
If you need to reduce the number of threads utilized by the SDK, this can be achieved using the OpenMP environment variable OMP_NUM_THREADS.
The SDK has been optimized to reduce latency. If you instead want to increase throughput, then limit the number of threads and instead run inference using multiple
instances of the SDK in parallel.
The following graph shows the impact of threads on inference speed.
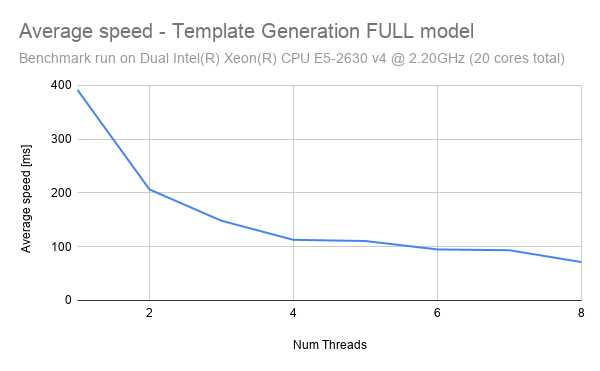
As can be seen, the graph follows an exponential decay pattern, with the greatest reduction in latency being experiences when moving from 1 thread to 2 threads. The significance of this is that we can actually enforce a reduced thread count in order to increase the CPU throughput. Consider an example where we have a CPU with 8 threads.
Scenario 1: Latency Optimized: In this scenario, we have 1 instance running inference using all 8 threads. Using the chart above, we can approximate the latency to be 75ms - given a single input image, inference can be performed in 75ms. Therefore, this scheme optimizes to reduce latency as much as possible. However, if the instance is provided with 100 input images to process, then it will take a total of 7.5s (100 images * 75ms ) to run inference.
Scenario 2: Throughput Optimized: In this scenario, we have 8 instances running inference using only 1 thread each. Using the chart above, we can approximate the latency to be 400ms - given a single input image, inference will be performed in 400ms. Although this seems like a bad tradeoff compared to scenario 1, scenario 2 shines when we have many input samples. If the instances are provided with 100 input images to process, then it will take a total of 5s (100 images * 400ms / 8 instances) to run inference.
Hence, by running more instances in parallel and reducing the number of threads per instance, we have increased the latency but also increased the overall throughput.
How can I run inference with multiple instances of the SDK on a single CPU?¶
Since a single instance of the SDK can use up to 8 threads for inference, most 4 core / 8 thread CPUs will work optimally with only a single instance of the SDK. Running multiple instances of the SDK will utilize more than 8 threads total and will result in time slicing which will slow things down. If you want to use multiple instances, then you must reduce the number of threads used for inference (refer to “How can I reduce the number of threads used by the SDK?” question above). So for example, if you limit the number of threads used for inference to just 4, then you can optimally run 2 instances of the SDK on your 4 core / 8 thread CPU.
How can I increase throughput?¶
CPU: Throughput can be increased on CPU by running multiple instances of the SDK in parallel, and allocated fewer threads to each instance. See the question titled “How can I reduce the number of threads used by the SDK?” for more information.
GPU: Throughput can be increased on GPU by using batching. Currently only our face recognition module supports batch inference. You can also increase throughput (and decrease latency) by using images pre-loaded in GPU (ex. decode video stream directly into GPU ram).
Is the SDK threadsafe?¶
In CPU only mode, the SDK is threadsafe.
However, note that the Trueface::SDK::setImage() function is stateful and therefore necessary precautions should be taken.
We also don’t advise running inference functions (face detection, face recognition, object detection, etc) in parallel using the same SDK instance as it will be slower than running inference in serial (on a standard 4 core / 8 thread CPU using the default number of threads for inference); therefore use a worker queue architecture, more on this below.
In GPU mode, the SDK is not threadsafe. You should also avoid creating multiple SDK instances for the same GPU index. However, you can create an instance of the SDK for each GPU your machine has (and assign the GPU index accordingly).
What architecture should I use when I have multiple camera streams producing lots of data?¶
For simple use cases, you can connect to a camera stream and do all of the processing directly onboard a single devices.
The following approaches are ideal for situations where you have tons of data to process.
The first approach to consider is a publisher/subscriber architecture.
Each camera producing data should push the image into a shared queue, then a worker or pool of workers can consume the data in the queue and perform the necessary operations on the data using the SDK. For a highly scalable design, split up all the components into microservices which can be distributed across many machines (with many GPUs) and use a Message Queue system such as RabbitMQ to facilitate communication and schedule tasks for each of the microservices. For maximum performance, be sure to use the GPU batch inference functions (see batch_fr_cuda.cpp sample app) and use images in GPU RAM (see face_detect_image_in_vram.cpp sample app).
Another approach is to process the camera stream data directly at the edge using embedded devices then either run identify at the edge too, or if dealing with massive collections, send the resulting Faceprints to a server / cluster of servers to run the identify calls.
Refer to the “1 to N Identification” tab (on the left) for more information on this approach.
Finally, you can manage a cluster of Trueface Visionbox instances using kubernetes or even run the instances on auto scaling cloud servers and post images directly to those for processing.
These are just a few of the popular architectures you can follow, but there are many other correct approaches.
Points to note: Each SDK instance can use up to 8 threads for inference on CPU. Being mindful of this, only create as many CPU workers (each with their own SDK instance) as your CPU can support (on most 4 core CPUs you should only have one instance of the CPU SDK running), otherwise performance will be negatively impacted. Refer to “How can I reduce the number of threads used by the SDK?” question above for more details.
What is the difference between the static library and the dynamic library?¶
The static library libtf.a is the CPU only library, while the dynamic library libtf.so offers GPU and CPU support.
What hardware does the GPU library support?¶
The x86-64 GPU enabled SDK supports NVIDIA GPUs with GPU Compute Capability 5.2+, and currently supports CUDA 10.1 and CUDA 11.2. The AArch64 GPU enabled SDK supports NVIDIA GPUs with GPU Compute Capability 5.3+, and currently supports CUDA 10.2 (default on NVIDIA Jetson devices).
You can determine your GPU Compute Capability here.
Why is my license key not working with the GPU library?¶
The GPU library requires a different token which is generally tied to the GPU ID. Please speak with a sales representative to receive a GPU token.
Why does the first call to an inference function take much longer than the subsequent calls?¶
Our modules use lazy initialization meaning the machine learning models are only loaded into memory when the function is first called instead of on SDK initialization. This ensure minimal memory overhead from unused modules. When running speed benchmarks, be sure to discard the first inference time.
How do I use the python bindings for the SDK?¶
In order to run the sample apps, you must place the python bindings library libtf.* in the same directory as the python script.
Alternatively, you can add the directory where the python bindings library resides to your PYTHONPATH environment variable.
If using the GPU library, you must add the directory where the GPU library libtf.so resides to your LD_LIBRARY_PATH environment variable.
All you need to do from there is add import tfsdk in your python script and you are ready to go.
How do I choose a similarity threshold for face recognition?¶
Navigate here and use the ROC curves to select a threshold based on your use case. Refer to this blog post for advice on reading ROC curves.
What are the differences between the face recognition models?¶
The Trueface::FacialRecognitionModel::LITE model is a lightweight model which has been optimized to minimize latency and resource usage (RAM). This comes at a reduction in accuracy.
It is therefore advised that this model only be used for low accuracy 1 to 1 matching use cases, embedded devices with limited computing ability, or prototyping.
The Trueface::FacialRecognitionModel::FULL model (TFV4) has better accuracy than the Trueface::FacialRecognitionModel::LITE model, but also has greater inference time and RAM usage.
It is advised for 1 to N use cases, and we suggest that you run this model using a GPU.
Note, TFV4 has now been deprecated and replaced by TFV5 which has better performance.
Despite this, we will continue providing support for TFV4 for clients with existing collections.
The Trueface::FacialRecognitionModel::TFV5 model is the replacement for the Trueface::FacialRecognitionModel::FULL (TFV4) model, and offers improved accuracy.
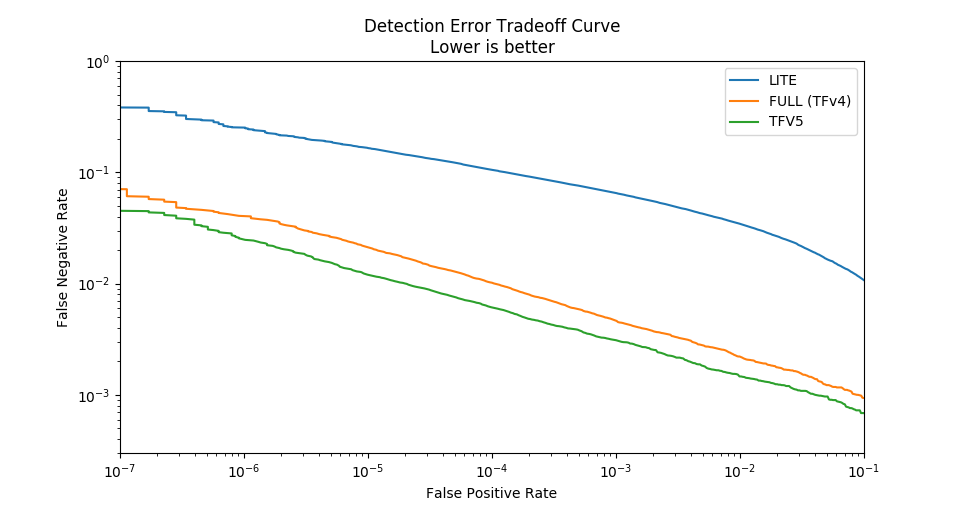
It has a 43% reduction in False Negative Rate compared to TFV4 (at a False Positive Rate of 10^-5)
This model has similar inference time and resource usage to the Trueface::FacialRecognitionModel::FULL model, so it is also advised you use this model with a GPU.
This model is ideal for 1 to N use cases, or use cases that require the highest accuracy.
Below is a Detection Error Tradeoff graph which shows the difference in performance between the three models. The DET graph plots the False Negative Rate against the False Positive Rate. A flatter and lower curve indicates better performance.
Are Faceprints compatible between models?¶
Faceprints are not compatible between models.
That means that if you have a collection filled with Trueface::FacialRecognitionModel::FULL model Faceprints, you will not be able to run a query against that collection using a Trueface::FacialRecognitionModel::TFV5 Faceprint.
The SDK has internal checks and will throw and error if you accidentally try to do this.
How can I upgrade my collection if is filled with Faceprints from a deprecated model?¶
As of right now, there is no way to upgrade your existing Faceprints to a new model (such as from Trueface::FacialRecognitionModel::FULL to Trueface::FacialRecognitionModel::TFV5).
For this reason, we will continue providing support for deprecated models so that if you have an existing collection containing Faceprints from a deprecated model, you do not need to worry about that model being removed in future releases.
With this in mind, we advise you to save your enrollment images in a database of your own choosing. That way, when we do release a new and improved face recognition model, you can re-generate Faceprints for all your images using the new model and enroll them into an updated collection.
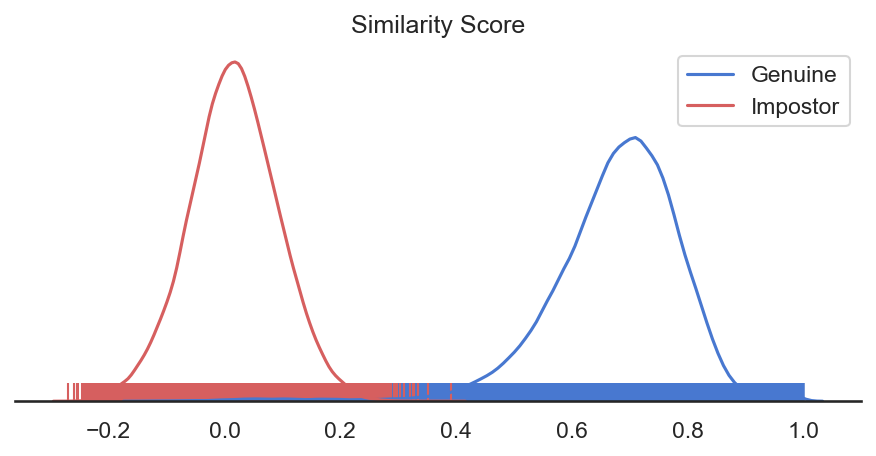
What is the difference between similarity score and match probability?¶
The similarity score refers to the similarity between two feature vectors. The similarity score values can range from -1 to 1. The match probability describes the probability that the two feature vectors belong to the same identity. The match probability can range from 0 to 1.
A regression model is used to transform the similarity score to match probability:

There are many face detection and recognition functions. Which should I use?¶
This depends on the use case, but a few of the most popular pipelines will be outlined below.
You start by calling Trueface::SDK::setImage(). You can either pass this function a path to an image on disk or an image buffer. Next, you have a few options:
1) You can straight away call Trueface::SDK::getLargestFaceFeatureVector() which will return the Trueface::Faceprint of the largest face in the image.
This is perfect for when you only care about the largest face, for example when enrolling a face into a collection.
2) Call Trueface::SDK::detectLargestFace() which will return the Trueface::FaceBoxAndLandmarks of the largest face in the frame. The Trueface::FaceBoxAndLandmarks can then be passed to
Trueface::SDK::getFaceFeatureVector() to generate the face feature vector. This flow is useful for when you require the bounding box coordinates,
such as for drawing a bounding box around the face.
3) Call Trueface::SDK::detectFaces() which will return a list of Trueface::FaceBoxAndLandmarks representing all the faces found in the frame. These faces can then be individually passed to
Trueface::SDK::getFaceFeatureVector() to generate the feature vectors, or you can call Trueface::SDK::extractAlignedFace() then Trueface::SDK::getFaceFeatureVectors() to batch generate the feature vectors. This flow is ideal for
situations where you want to run identification on every face in the image.
Regardless of which of these pipelines you use, the Trueface::Faceprint can then be passed to one of the 1 to N identification functions such as Trueface::SDK::identifyTopCandidate().
How do createDatabaseConnection and createLoadCollection work?¶
Trueface::SDK::createDatabaseConnection() is used to establish a database connection.
This must always be called initially before loading Faceprints from a collection or enrolling Faceprints into a new collection,
unless the Trueface::DatabaseManagementSystem::NONE options is being used, in which case it doesn’t need to be called and you can go straight to Trueface::SDK::createLoadCollection().
Next, the user must call Trueface::SDK::createLoadCollection() and provide a collection name.
If a collection with the specified name already exists in the database which we have connected to, then all the Faceprints in that collection will be loaded from the database collection into memory (RAM).
If no collection exists with the specified name, then a new collection is created. From here, the user can call Trueface::SDK::enrollTemplate() to save Faceprints to both the database collection and in-memory (RAM) collection.
If using the Trueface::DatabaseManagementSystem::NONE, a new collection will always be created on a call to this function, and the previous loaded collection - if this is not the first time calling this function - will be deleted (since it is only stored in RAM).
From here, the 1 to N identification functions such as Trueface::SDK::identifyTopCandidate() can be used to search through the collection for an identity.
Why are no faces being detected in my large images?¶
If the faces in your images are very large, then the face detector may not be able to detect the face using the default Trueface::ConfigurationOptions.smallestFaceHeight parameter.
The face detector has a detection scale range of about 5 octaves. Ex. 40 pixels yields the detection scale range of ~40 pixels to 1280 (=40x2^5) pixels.
If you are dealing with very large images, or with dynamic input images, it is best to set the Trueface::ConfigurationOptions.smallestFaceHeight parameter to -1.
This will dynamically adjusts the face detection scale range from image-height/32 to image-height to ensure that large faces are detected in high resolution images.
How can I speed up face detection?¶
You can speed up face detection by setting the Trueface::ConfigurationOptions.smallestFaceHeight parameter appropriately.
Increasing the Trueface::ConfigurationOptions.smallestFaceHeight will result in faster inference times, so try to set the Trueface::ConfigurationOptions.smallestFaceHeight as high as possible for your use case if speed is a critical requirement.
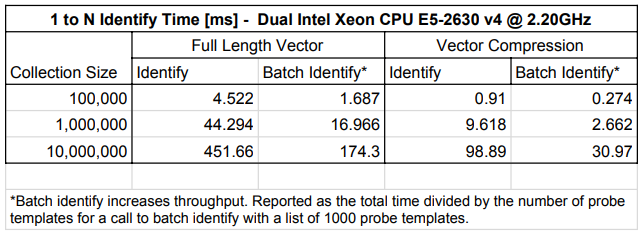
What does the frVectorCompression flag do? When should I use it?¶
The Trueface::ConfigurationOptions.frVectorCompression flag is used to enable optimizations in the SDK which compresses the feature vector and improve the match speed for
both 1 to 1 comparisons and 1 to N identification.
The flag should be enabled when dealing with massive collections or when matching is very time critical. Additionally, it should be used in environments with limited memory or disk space as it will reduce the feature vector memory footprint.
The following images compare the match speed with and without the optimization enabled:
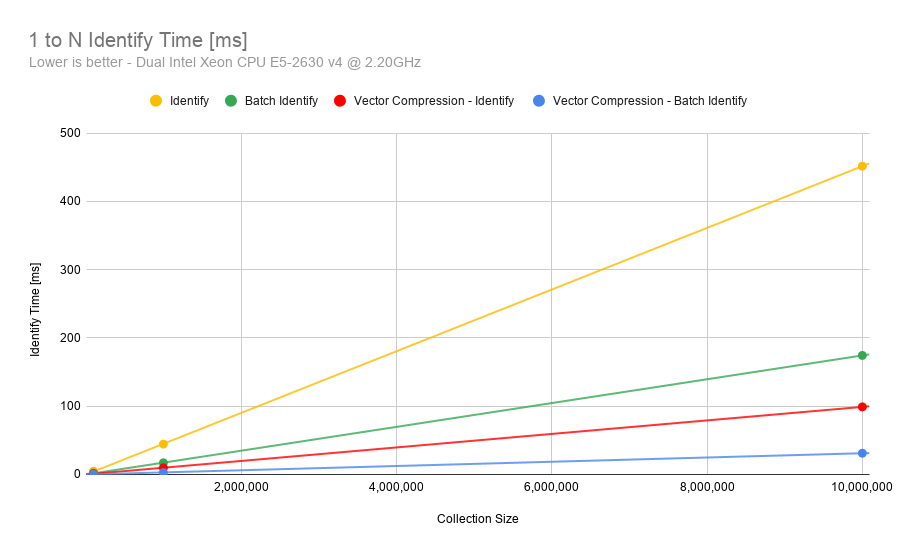
The trade off to using this flags is that it will cause a very slight loss of accuracy. However, the method has been optimized to ensure this loss is extremely minimal.