Environment Variables¶
The following environment variables can change the runtime behaviour of the SDK. Note, the variables must be set prior to initializing the SDK.
To set an environment variable in your shell, run export VARIABLE_NAME=VARIABLE_VALUE.
OMP_NUM_THREADS
Used to limit the maximum number of threads used by the SDK.
The SDK inference engines can use up to 8 threads each, but this is dependant on the number of cores your system has.
The batchIdentifyTopCandidate function is capable of using all cores on your machine, depending on the number of probe Faceprints provided.
To limit the number of threads used by the SDK, use the OMP_NUM_THREADS environment variable.
The SDK has been optimized to reduce latency. If you instead want to increase throughput, then limit the number of threads and instead run inference using multiple
instances of the SDK in parallel.
The following graph shows the impact of threads on inference speed.
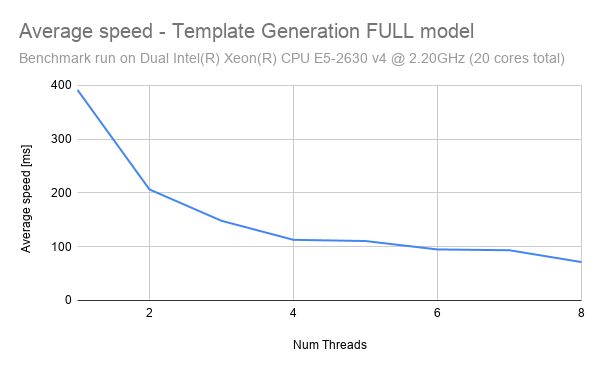
As can be seen, the graph follows an exponential decay pattern, with the greatest reduction in latency being experiences when moving from 1 thread to 2 threads. The significance of this is that we can actually enforce a reduced thread count in order to increase the CPU throughput. Consider an example where we have a CPU with 8 threads.
Scenario 1: Latency Optimized: In this scenario, we have 1 instance running inference using all 8 threads. Using the chart above, we can approximate the latency to be 75ms - given a single input image, inference can be performed in 75ms. Therefore, this scheme optimizes to reduce latency as much as possible. However, if the instance is provided with 100 input images to process, then it will take a total of 7.5s (100 images * 75ms ) to run inference.
Scenario 2: Throughput Optimized: In this scenario, we have 8 instances running inference using only 1 thread each. Using the chart above, we can approximate the latency to be 400ms - given a single input image, inference will be performed in 400ms. Although this seems like a bad tradeoff compared to scenario 1, scenario 2 shines when we have many input samples. If the instances are provided with 100 input images to process, then it will take a total of 4s (100 images * 400ms / 8 instances) to run inference.
Hence, by running more instances in parallel and reducing the number of threads per instance, we have increased the latency but also increased the overall throughput.
ex. export OMP_NUM_THREADS=4
TF_LOG_LEVEL
Used to set the log level of the SDK. Options include TRACE, DEBUG, INFO, WARN, ERROR, and OFF.
Default log level is INFO.
ex. export TF_LOG_LEVEL=WARN